RetNet 论文笔记
RETNET 论文笔记
RETNET(全称Retentive Network),是微软研究院和清华大学推出的大语言模型(LLM)基本架构。从论文题目可以看出,RETNET在LLM上要优于Transformer,同时实现了平行训练、低耗费推理和良好表现三大特性。RETNET的理论来源是连接循环和注意力,提出了对序列模型的记忆力机制,这支持三个模式,即:平行、循环和分块循环(chunkwise recurrent)。平行意味着允许平行训练;循环意味着可以在O(1)耗费下推理,这可以在不牺牲性能的情况下提高解码吞吐量、降低延迟和减少GPU内存使用;分块循环意味着便于具有线性复杂度的高效长序列建模,每个chunk都可以并行编码。相关代码见https://aka.ms/retnet。
1 介绍
现在,Transformer已然成为LLM的首选架构。当时提出Transformer架构是为了克服基于RNN的模型的无法并行训练的问题,然而,Transformer的并行训练是有代价的,即推理时比较低效,因为每个step的复杂度都是O(N),并且要在内存中缓存key-value。这导致了部署基于Transformer的模型不是很友好,随着序列长度的增加,GPU的内存急剧增加,推理速度急速下降。
因此,也有很多人在努力,希望提出一个在保持平行训练和良好表现的前提下,能够实现具有O(1)复杂度的推理的架构。这是很难的,即所谓“不可能三角”:
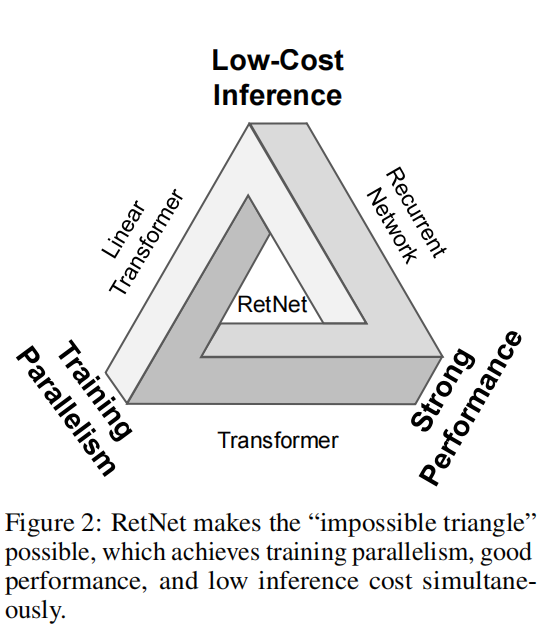
RETNET则可以同时实现低成本推理、高效长序列建模、和Transformer相似的性能和并行训练。具体来说,作者提出了多尺度保留机制(multi-scale retention mechanism)代替多头注意力(multi-head attention)。它有三种计算范式,即并行、循环和块递归表示。首先,并行表示使训练并行性能够充分利用GPU设备。其次,递归表示能够在内存和计算方面实现有效的O (1)推断。可以显著降低部署成本和延迟。此外,该实现比较简单,没有键值缓存。第三,分块的循环表示可以执行有效的长序列建模。作者对每个本地块进行并行编码以提高计算速度,同时递归地编码全局块以节省GPU内存。
语言模型的实验结果表明,RetNet在尺度曲线和上下文学习方面都具有竞争力。此外,RetNet的推理耗费是不受序列长度影响的。对于7B型号和8k序列长度,RetNet的解码速度比具有键值缓存的Transformer快8.4倍,节省了70%的内存。在训练过程中,RetNet还比使用了FlashAttention的Transformer节省了25-50%的内存,提升了7倍的速度。此外,RetNet的推理延迟对batch size不敏感,允许巨大的吞吐量。这些特性使RetNet可以成为大型语言模型的Transformer的强大继承者。
2 Retentive Networks
RETNET由L个相同的block组成,与Transformer相似(residual connection, and pre-LayerNorm)。每个RETNET block包括两个模块:多尺度保留模块(multi-scale retention, MSR)和前馈网络(feed-forward network, FFN)模块。
具体可表示为:给定一个输入序列,RETNET通过自回归的方式编码这个序列。输入向量首先被转换为(是隐层维数),说白了应该是这样形状的矩阵:
然后,一层一层地计算:。
2.1 Retention
给定输入,我们把它投影到一维函数上,现在,通过状态来把映射到上,为了简化,我们规定。那么有:
(上面两个等式称为(1))
【注:这个Q和K,应该指的是Query和Key,即Q K V中的】
接下来,我们使用投影进行内容感知:
(上面的等式称为(2))
这里的指的是可学习的矩阵。
下面,我们把矩阵对角化:,这里的。这样我们可以得到。通过吸收到中,我们可以重写(1)式:
(上面的等式称为(3))
其中,称为xPos,这是Transformer的相对位置embedding。我们进一步地把简化为一个标量,等式(3)变为:
其中表示共轭转置。该公式在训练实例中很容易被并行化。
Retention的平行表示。Retention Layer结构图如下:
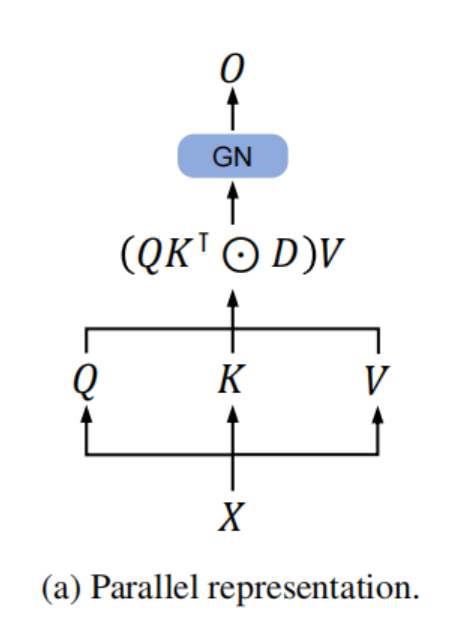
Layer的定义如下:

与自注意力类似,并行表示使能够有效地用GPU训练模型。
伪代码如下:
def ParallelRetention(
q, # bsz ∗ num_head ∗ len ∗ qk_dim
k, # bsz ∗ num_head ∗ len ∗ qk_dim
v, # bsz ∗ num_head ∗ len ∗ v_dim
decay_mask # num_head ∗ len ∗ len
):
retention = q @ k.transpose(−1, −2)
retention = retention ∗ decay_mask
output = retention @ v
output = group_norm(output)
return output
Retention的循环表示。如图b,所提出的机制也可以写成RNN,这有利于推理。对于第n个时间步长,我们递归地得到的输出为:
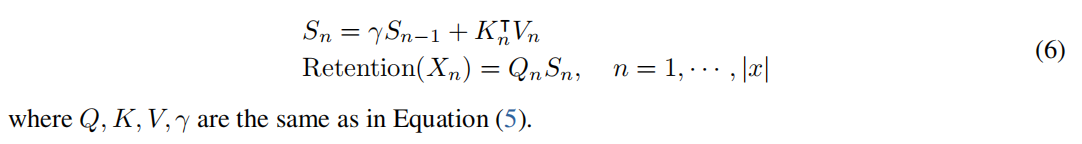
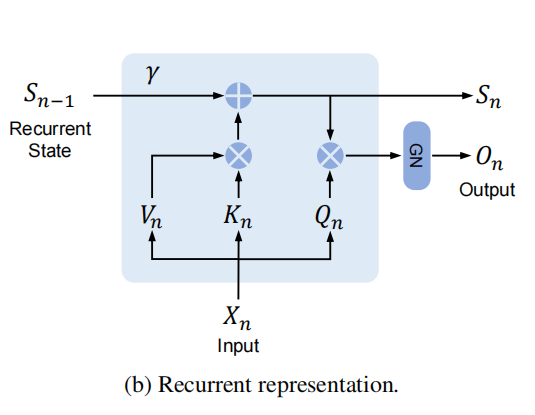
伪代码如下:
def RecurrentRetention(
q, k, v, # bsz ∗ num_head ∗ len ∗ qkv_dim
past_kv, # bsz ∗ num_head ∗ qk_dim ∗ v_dim
decay # num_head ∗ 1 ∗ 1
):
current_kv = decay ∗ past_kv + k.unsqueeze
(−1) ∗ v.unsqueeze(−2)
output = torch.sum(q.unsqueeze(−1) ∗
current_kv, dim=−2)
output = group_norm(output)
return output, current_kv
Retention的块循环表示。一种并行表示和循环表示的混合形式可用于加速训练,特别是对于长序列。我们将输入序列划分成块。在每个块中,我们遵循并行表示(公式(5))来进行计算。相反,交叉块信息按照循环表示方式传递(公式(6))。具体来说,设B表示块的长度。我们通过以下方法计算第i个块的Retention输出:
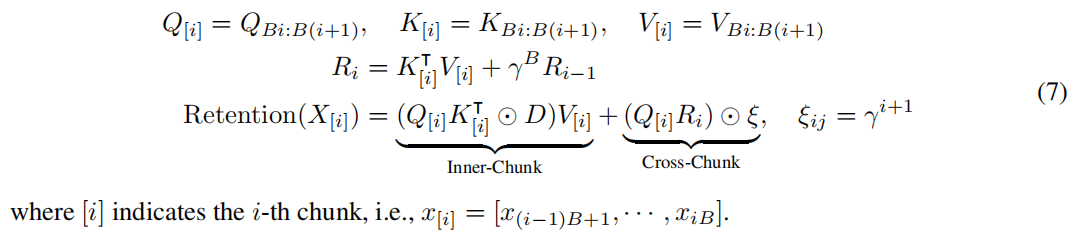
伪代码如下:
def ChunkwiseRetention(
q, k, v, # bsz ∗ num_head ∗ chunk_size ∗ qkv_dim
past_kv, # bsz ∗ num_head ∗ qk_dim ∗ v_dim
decay_mask, # num_head ∗ chunk_size ∗ chunk_size
chunk_decay, # num_head ∗ 1 ∗ 1
inner_decay, # num_head ∗ chunk_size
):
retention = q @ k.transpose(−1, −2)
retention = retention ∗ decay_mask
inner_retention = retention @ v
cross_retention = (q @ past_kv) ∗ inner_decay
retention = inner_retention + cross_retention
output = group_norm(retention)
current_kv = chunk_decay ∗ past_kv + k.transpose(−1, −2) @ v
return output, current_kv
2.2 Gated Multi-Scale Retention
作者在每个layer中使用,其中d表示头维度(head dimension),不同的头使用不同的参数矩阵,而且,多尺度保留(multi-scale retention, MSR)对不同的头指定了不同的。为了简单起见,我们在不同的层之间设置了相同的,并保持它们不变。此外,作者引入了倾斜门(swish gate)以增加retention layers的非线性。这样,给定,我们定义layer为:

Retention分数归一化。作者用GroupNorm的尺度不变性来提高retention layers的数值精度。具体来说,在GroupNorm中乘一个标量不会影响输出和反向梯度,即。作者在等式(5)中实现了三个归一化因子。第一,正规化为;第二,将变为;第三,让表示retention scores ,正规化为,这样,retention的输出变为 。由于尺度不变的性质,上述技巧在稳定正向和反向通道的数值流动的同时,并不影响最终的结果。
2.3 ❇️Retention网络的整体架构
对于L层的Retention网络,作者堆叠多尺度缩放retention(multi-scale retention, MSR)和前馈网络(FFN)。输入序列通过word embedding层转为向量,然后用这个向量(是隐层维数)作为模型的输入,并且通过下列公式计算模型的输出:
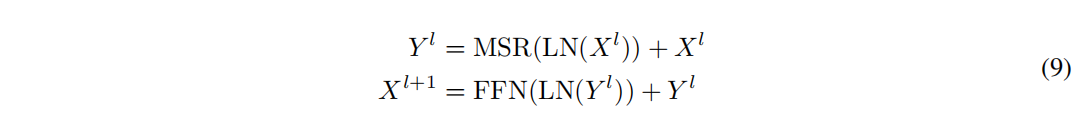
上述公式中,LN表示LayerNorm,,是参数矩阵。
训练。在训练过程中,作者使用了平行模式(公式5)和块循环模式(公式7)。这两个模式可以利用GPU加速计算。特别地,分块训练对长序列训练特别有用,这在FLOPs和内存消耗方面都是比较好的。
推理。推理过程中,作者使用了循环模式(公式6),这可以较好地拟合自回归解码。并且这可以在获得相同结果的同时,以O(1)复杂度执行。