LLaMA 2 论文笔记
LLaMA 2 论文笔记
该论文篇幅巨大,非常详细地介绍了LLaMA 2的预训练和微调过程,本篇笔记对其内容进行简要记录。论文链接
1 介绍
LLaMA 2共包括两大版本:预训练模型LLaMA 2和基于它的微调模型LLaMA 2-Chat。共有7B 13B 34B 70B四种参数规模。
LLaMA 2,是LLaMA 1的升级版本,在多个公开可获得数据上进行训练。相比LLaMA 1,LLaMA 2预训练的语料库增加了40%,上下文长度(即可接受的输入长度)增加一倍(最多支持4K token),并且采用了分组查询注意力(grouped-query,后续有介绍)机制。
LLaMA 2-Chat是基于LLaMA 2预训练模型微调得来的,后续有详细介绍。
在第2节,本文介绍LLaMA 2的预训练方法;在第3节,本文介绍LLaMA 2-Chat的微调方法;
2 预训练方法
LLaMA 2的预训练特性如下:
- LLaMA 2基本还是采用LLaMA 1的训练方法:LLaMA 1论文链接
- 优化的自回归Transformer(归一化、激活函数等有变化,下面有介绍)
- 具体而言,LLaMA 2执行了更稳健的数据清理,更新了数据混合,对总token进行了40%以上的训练,将上下文长度增加了一倍,并使用分组查询注意力(GQA)来提高LLaMA 2的推理可扩展性

(2T = 2 trillion = 2万亿)
2.1 训练数据
LLaMA 2的训练数据来自混合后的公开数据,共在2T token上进行训练。
2.2 训练详情
预训练的设置和模型架构和LLaMA 1基本一致:
- Transformer架构
- 归一化 RMSNorm
- 激活函数 SwiGLU
- 旋转位置Embedding RoPE rotary positional embeddings,这个现在都在用,包括GLM
- 与LLaMA 1差异:增加了上下文长度、增加了GQA
A.2.1 额外的预训练信息之与LLaMA 1的变化内容介绍 p.46
- 上下文长度 更长的上下文长度可以让模型处理更多信息,这可以让模型支持记住更多对话历史信息、更多的总结任务、理解更长的文本
- Grouped-Query Attention 自回归解码的标准做法是缓存序列中先前token的key(K)和value(V)对,从而加快注意力计算。然而,随着context window或batch size的增加,与多头注意力(MHA)模型中的KV缓存大小相关的内存成本显著增长。对于KV缓存大小成为瓶颈的大型模型,可以在多个头之间共享key和value预测,而不会导致性能大幅下降。可以使用具有单个KV投影的原始多查询格式(MQA)或具有8KV投影的分组查询注意力(GQA)变体。基于消融结果和易于缩放推断,对于34B和70B Llama 2模型,LLaMA 2选择使用GQA而不是MQA。
- 额外发现:一个多卡并行训练的论文:Training multi-billion parameter language models using model parallelism
预训练超参设置
- AdamW优化器 β1=0.9,β2=0.95,eps=10e-5
- 余弦学习率,warmup 2000 steps
- 将最终学习率降低到峰值学习率的10%
- 使用0.1的权重衰减和1.0的梯度剪裁
预训练Tokenizer
使用与LLaMA 1相同的标记器;它采用了字节对编码(BPE)算法,使用了来自SentencePiece的实现。与LLaMA 1一样,将所有数字拆分为单个数字,并使用字节分解未知的UTF-8字符。总词汇大小为32k个标记。
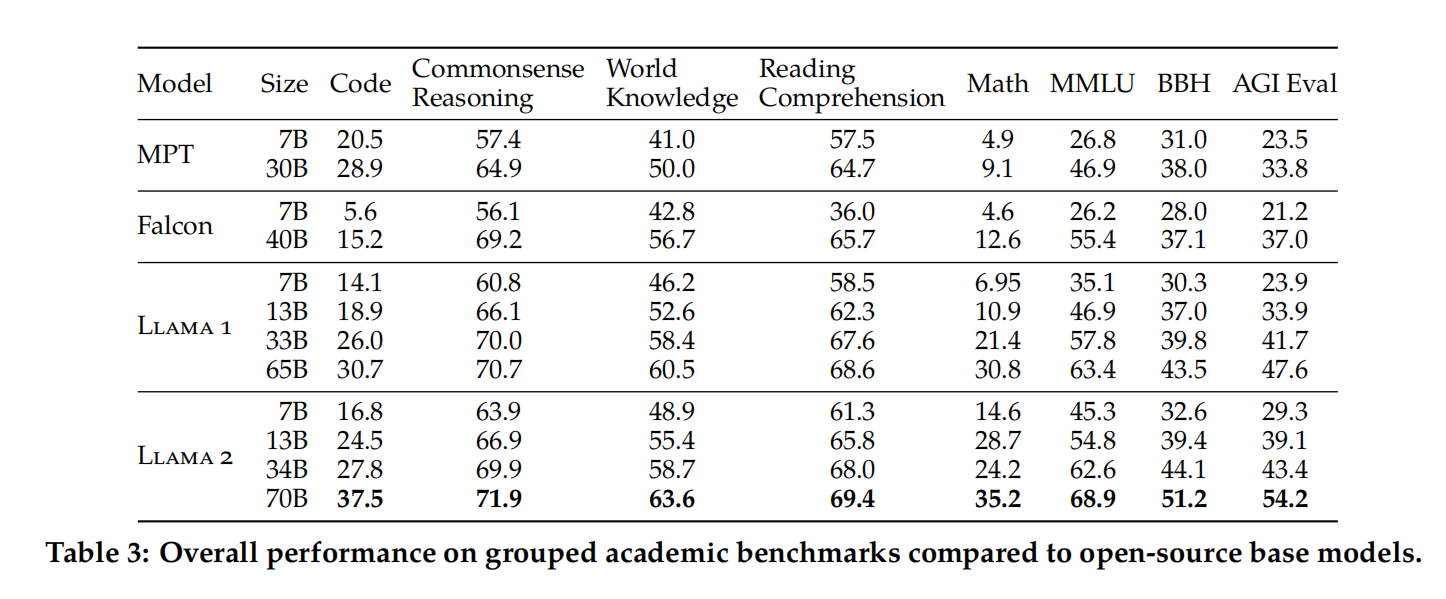
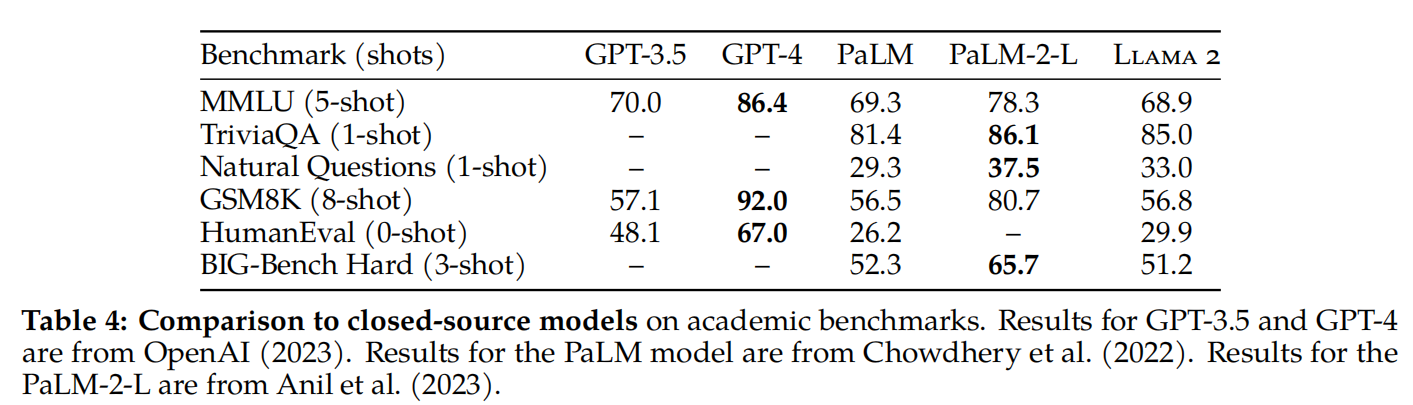
2.3 评测
评测结果如下:
3. Fine-tuning
- LLaMA 2-Chat基于LLaMA 2微调而来,包括指令微调和RLHF
- 本节报告了使用监督微调以及初始和迭代奖励建模和RLHF进行的实验和发现。
- 提出一种新技术,Ghost Attention (GAtt),用于帮助控制多轮对话流
3.1 Supervised Fine-Tuning (SFT)
开始:用公开可获得的指令微调数据,和LLaMA 1一致,使用了 Scaling Instruction-Finetuned Language Models
公开的指令微调数据质量参差不齐,首先就是要收集大量的高质量SFT数据,如下图:

高质量指令微调数据,即使是少量的,也可以让结果很好。万级别的好的数据足够了,Meta总共收集了27540个好数据。
- 对于监督微调,使用了余弦学习率,LR=2e-5,权重衰减=0.1,batch size = 64,sequence lenght = 4096
- 对于微调过程,每个样本都包含一个提示和一个答案。为了确保模型序列长度正确填充,作者将训练集中的所有提示和答案连接起来。使用一个特殊的令牌来分隔提示段和应答段。作者使用自回归目标,并从用户提示中消除令牌的损失,因此,作者只对回答令牌进行反向传播。最后,作者对模型进行了2个epochs的微调。
3.2 RLHF
3.2.1 人类偏好数据收集
与其他方案相比,作者选择了二进制比较协议,主要是因为它使作者能够最大限度地提高收集到的提示的多样性。作者的注释过程如下。作者要求注释器首先编写一个提示,然后根据提供的标准在两个采样的模型响应之间进行选择。为了最大限度地提高多样性,从两个不同的模型变量中对给定提示的两个响应进行采样,并改变温度超参数。除了给参与者一个被迫的选择之外,作者还要求注释者标注他们更喜欢自己选择的回答而不是选择的程度:要么他们的选择明显更好,要么更好,要么稍微好一点,要么好到可以忽略不计/不确定。
(就是给个输入,然后有两种输出,看哪个更符合标准)
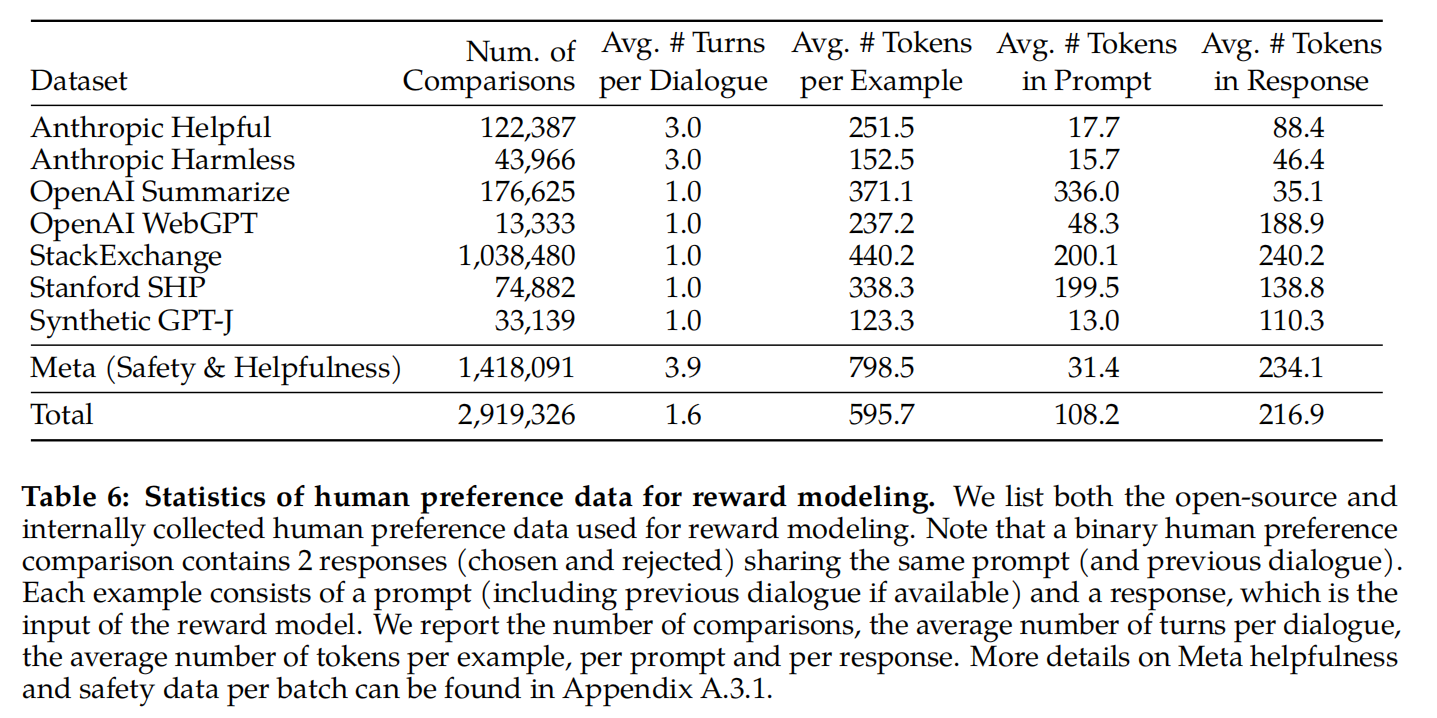
用到的一些人类偏好开源数据集
3.2.2 奖励建模
奖励建模就是拿一个模型的结果和它相关的Prompt作为输入,然后输出一个分数来表明这个结果的质量(有用性、安全性等),用这个分数,就可以在RLHF中优化模型了
为了训练奖励模型,作者将收集的成对人类偏好数据转换为二元排名标签格式(即选择和拒绝),并强制选择的响应比对应的响应具有更高的分数。作者使用了二元排名损失:
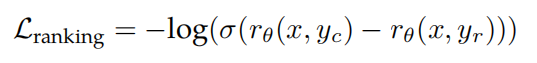
where rθ(x, y) is the scalar score output for prompt x and completion y with model weights θ. yc is the preferred response that annotators choose and yr is the rejected counterpart.
在这种二元排名损失的基础上,作者进一步修改它,如第3.2.1节所示,利用这些信息来明确教导奖励模型为具有更多差异的世代分配更多不一致的分数可能是有用的。为此,作者在损失中进一步添加了一个margin成分:
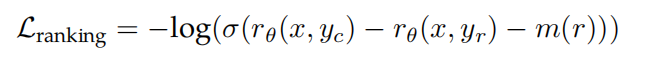
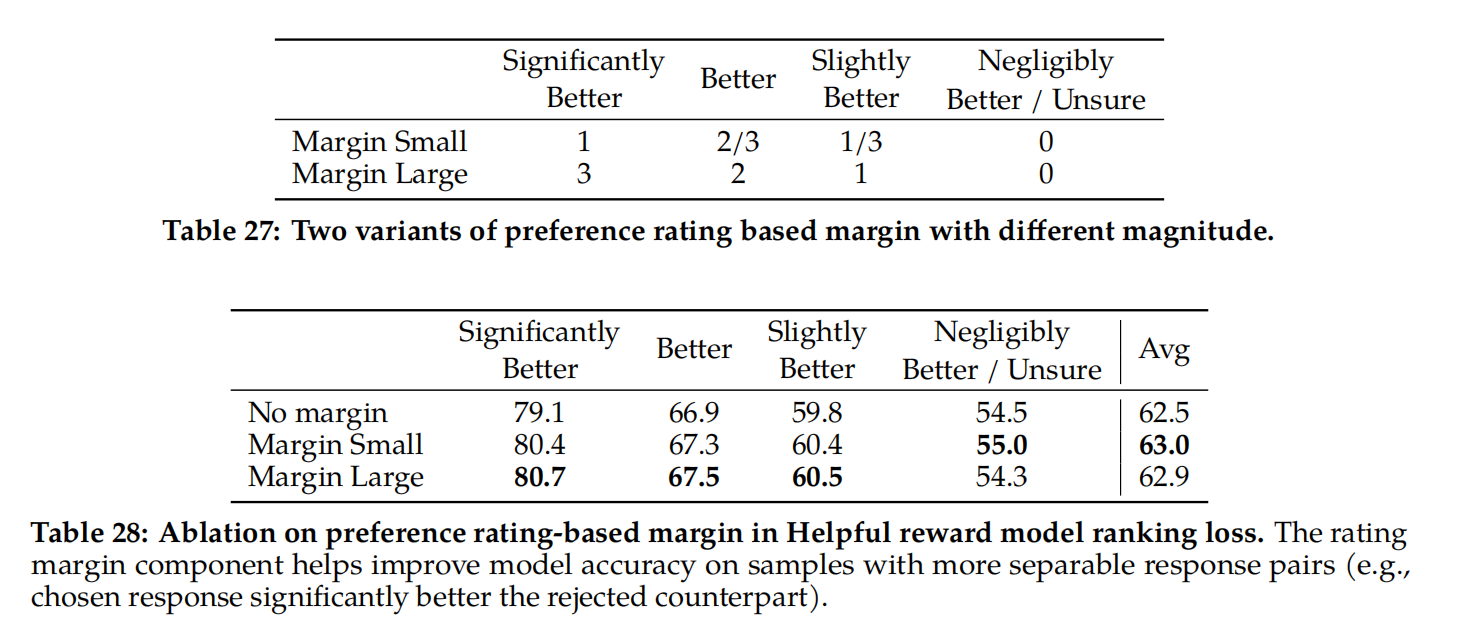
where the margin m(r) is a discrete function of the preference rating. Naturally, we use a large margin for pairs with distinct responses, and a smaller one for those with similar responses (shown in Table 27). We found this margin component can improve Helpfulness reward model accuracy especially on samples where two responses are more separable. More detailed ablation and analysis can be found in Table 28 in Appendix A.3.3.
奖励建模的训练详情。LLaMA 2-Chat在训练数据上训练一个epoch。在早期的实验中,发现训练时间过长会导致过度拟合。LLaMA 2-Chat使用与基本模型相同的优化器参数。70B参数LLaMA 2-Chat的最大学习率为5×10−6,其余参数为1×10−5。学习率按余弦学习率计划降低,降至最大学习率的10%。 LLaMA 2-chat使用占总步数3%的warm-up,最少5 steps。有效batch大小固定为512对,即每batch 1024行。
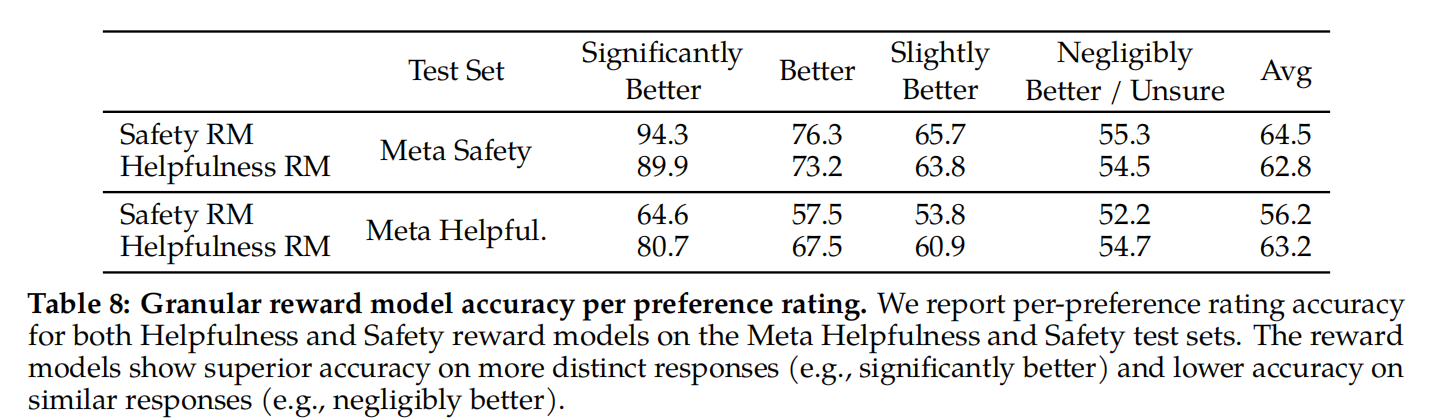
奖励建模的结果。在每一batch用于奖励建模的人类偏好注释上,都拿出1000个例子作为测试集来评估模型(这个都是可以学习的地方,按他的来)。作者将相应测试集的所有提示的并集分别称为“Meta Helpfulness”和“Meta Safety”。总体而言,这个奖励模型优于所有base-line,包括GPT-4。
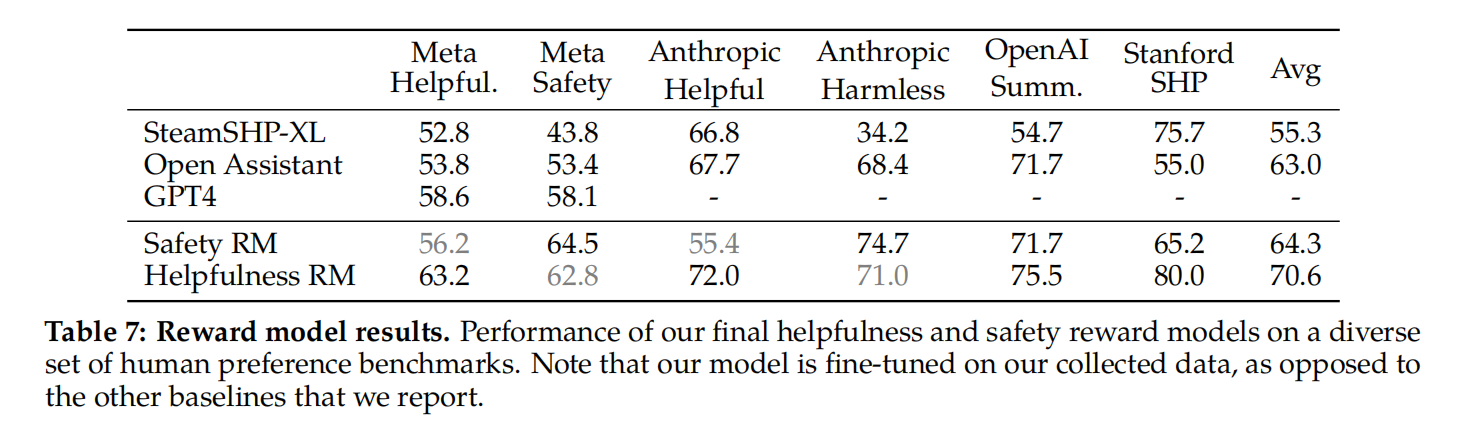
当作者在表8中按偏好评级对分数进行分组时,我们可以看到“明显更好”的测试集,并随着比较对变得更加相似而逐渐退化(例如,“稍微好一点”)。当在两个相似的模型反应之间做出决定时,由于注释者的主观性和他们对可能区分反应的细微细节的依赖,学习对人类偏好进行建模将变得具有挑战性。作者强调,对于提高LLaMA 2-Chat的性能,更明显的响应的准确性最为重要。与相似对相比,在更明显的反应上,人类偏好注释一致率也更高。
3.2.3 迭代微调
作者通过两个主要的算法来探索RLHF微调:
- 近端策略优化(Proximal Policy Optimization, PPO),论文链接,该算法是RLHF文献的标准。
- 拒绝采样微调(Rejection Sampling fine-tuning),作者对模型中的K个输出进行采样,并用我们的奖励选择最佳候选者,这与Constitutional AI: Harmlessness from AI Feedback保持一致。Residual Energy-Based Models for Text Generation也提出了同样的LLM重新排序策略,其中奖励被视为能量函数。在这里,作者更进一步,使用选定的输出进行梯度更新。对于每个Prompt,获得最高奖励分数的样本被视为新的金标准。与Discriminative Adversarial Search for Abstractive Summarization类似,然后作者在新的一组排序样本上微调模型,以增强奖励。
这两个强化学习(RL)算法的主要不同:
- 广度。在拒绝采样中,该模型为给定提示探索K个样本,而对PPO只进行一次生成。
- 深度。在PPO中,在步骤t的训练期间,样本是前一步骤的梯度更新后从t−1更新的模型策略的函数。在拒绝采样微调中,在应用类似于SFT的微调之前,作者在给定模型的初始策略的情况下对所有输出进行采样,以收集新的数据集。然而,由于作者应用了迭代模型更新,两种RL算法之间的基本差异就不那么明显了。
拒绝采样的介绍。作者只对最大的70B LLaMA 2-Chat进行拒绝采样。所有较小的模型都根据较大模型的拒绝采样数据进行微调,从而将较大模型的能力提取到较小的模型中。在每个迭代过程,作者从最新的模型中对每个Prompt采样K个答案,作者为每个样本打分,给出实验时可访问的最佳奖励模型,然后为给定提示选择最佳答案。
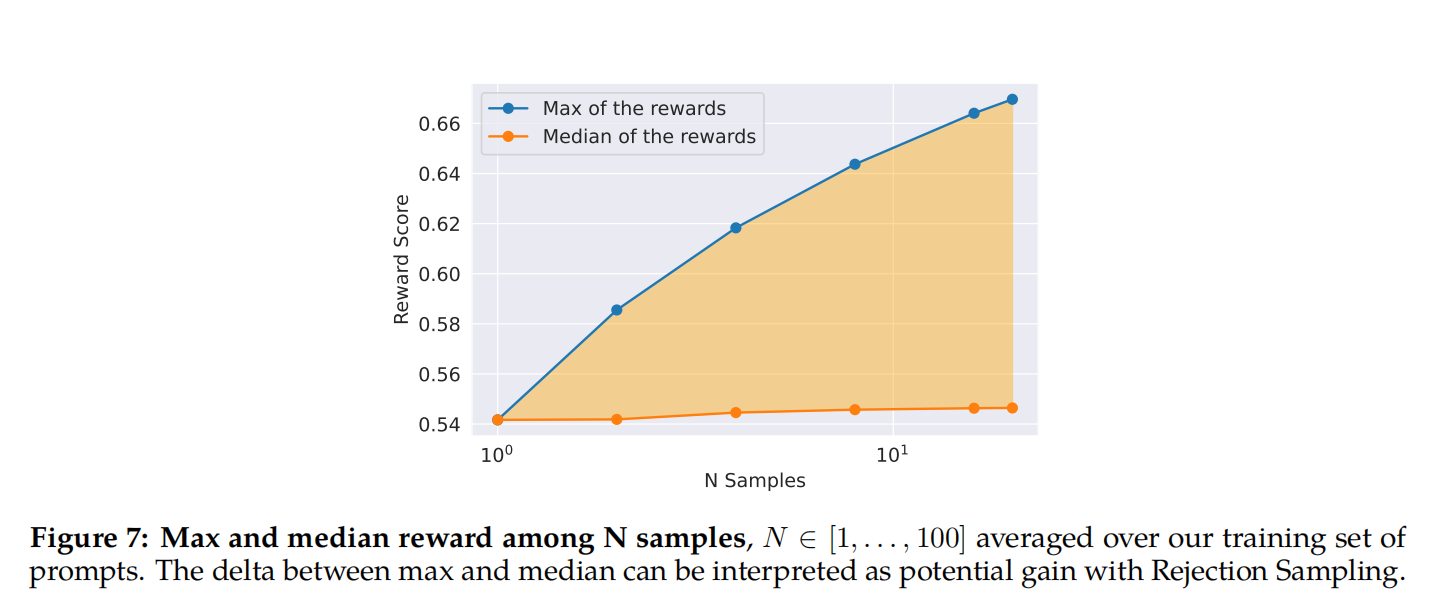
作者在图7中说明了拒绝采样的好处。最大曲线和中值曲线之间的增量可以解释为对最佳输出进行微调的潜在增益。正如预期的那样,这个增量随着样本的增加而增加,因为最大值增加(即,更多的样本,产生良好轨迹的机会更多),而中值保持不变。探索和作者能在样本中获得的最大回报之间有着直接的联系。温度参数对勘探也起着重要作用,因为更高的温度使作者能够对更多样的输出进行采样。
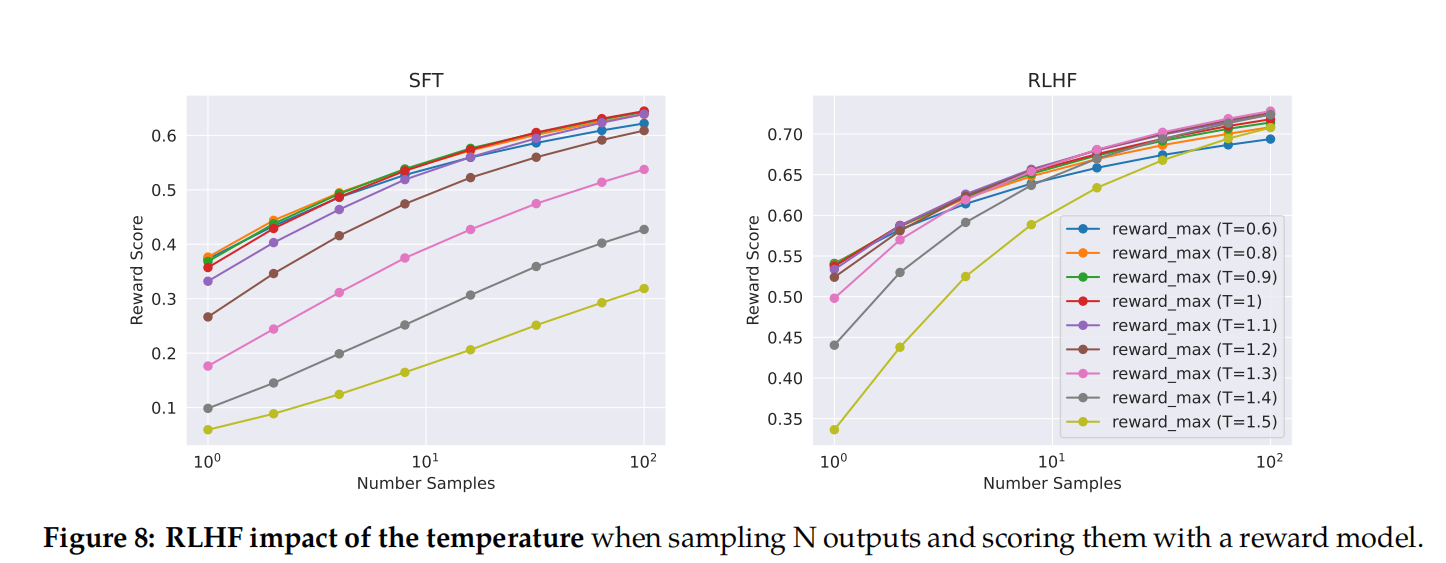
在图8中,作者报告了LLaMA 2-Chat-SFT(左)和LLaMA 2-Chat-RLHF(右),N个样本(其中N∈[1,…,100])在不同温度下的最大回报曲线。可以观察到,在迭代模型更新过程中,最佳温度不是恒定的:RLHF对重新缩放温度有直接影响。对于LLaMA 2-Chat-RLHF,当在10到100个输出之间采样时,最佳温度为T∈[1.2,1.3]。因此,在有限的计算预算下,有必要逐步重新调整温度。请注意,对于每个模型,这种温度重新缩放都会发生恒定数量的步骤,并且总是从每个新RLHF版本的基本模型开始。
PPO介绍。对于所有模型,作者使用AdamW优化器,其中β1=0.9,β2=0.95,eps=10−5。使用0.1的权重衰减(weight decay)、1.0的梯度剪裁(gradient clipping)和10e−6的恒定学习率(lr) 对于每个PPO迭代,我们使用512的批量大小(batch size)、0.2的PPO剪辑阈值、64的小批量大小(mini-batch size),并且每个小批量采取一个梯度步骤(step)。对于7B和13B模型,我们设置β=0.01(KL惩罚),对于34B和70B模型,设置β=0.005。
作者为所有模型进行了200到400次迭代的训练,并对延迟的提示进行了评估,以提前停止。70B模型上的PPO每次迭代平均耗时≈330秒。为了快速进行大批量训练,作者使用PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel。这在使用O(1)正向或反向传播时是有效的,但在生成过程中会导致很大的减慢(≈20×),即使在使用大批量和KV缓存时也是如此。作者能够通过在生成之前将模型权重合并到每个节点一次,然后在生成之后释放内存,恢复训练循环的其余部分来缓解这种情况。
3.3 多轮一致性的指令
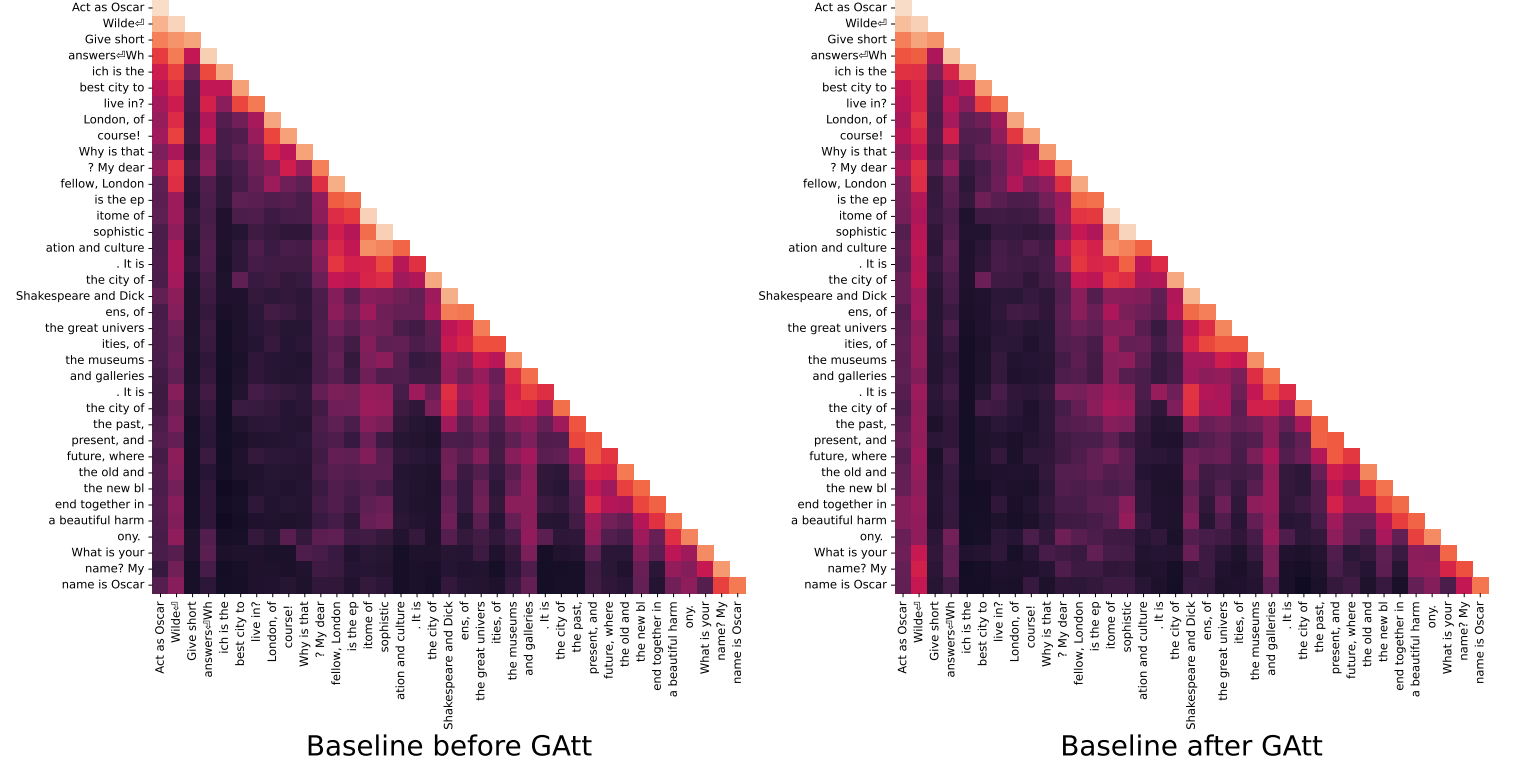
在对话设置中,一些指示应适用于所有的对话轮数中,例如,简洁地回应,或“扮演”某个公众人物。然而,在初始版本的RLHF模型中,LLaMA 2-Chat会忘记指示,如下图左侧(右侧是使用GAtt优化后的结果):
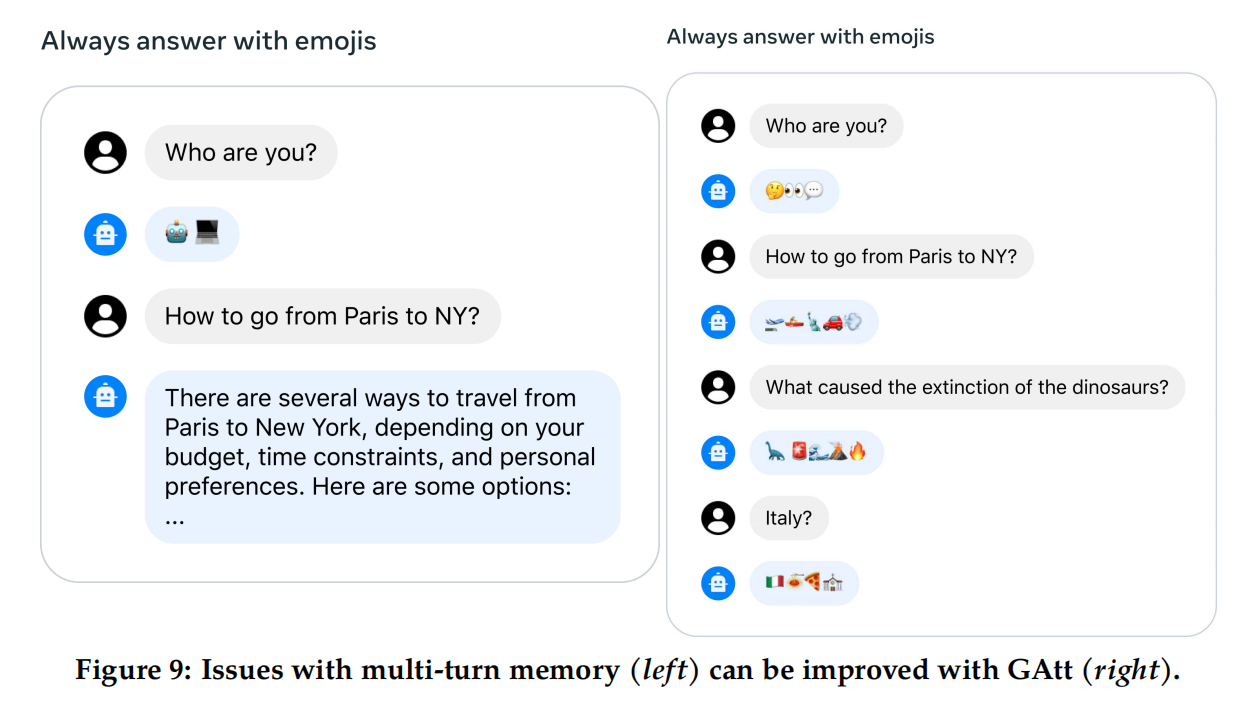
为了解决这些限制,作者提出了Ghost Attention(GAtt),这是一种受上下文蒸馏,Constitutional AI: Harmlessness from AI Feedback启发的非常简单的方法,它可以破解微调数据,以帮助在多阶段过程中集中注意力。GAtt允许对多轮进行对话控制,如图9(右)所示。
Gatt方法。假设可以访问两个人(例如,用户和助手)之间的多回合对话数据集,该数据集具有消息列表[u1,a1,…,un,an],其中un和an分别对应于回合n的用户和助手消息。然后定义了一个指令,inst,应该贯穿在整个对话中。例如,inst可以是“扮演...”。然后可以将此指令综合连接到会话的所有用户消息。
接下来可以使用最新的RLHF模型对这些合成数据进行采样。现在有了一个上下文对话和样本,可以在类似于拒绝采样的过程中对模型进行微调。可以在除第一个回合外的所有回合中放弃它,而不是用指令来增加所有上下文对话回合,但这会导致系统消息(即最后一个回合之前的所有中间辅助消息)与样本在训练时间不匹配。为了解决这个可能影响训练的问题,只需将前几轮中的所有token(包括助手的消息)的loss设置为0。
对于训练指令,作者创建了一些综合约束条件:爱好(“你喜欢例如网球”)、语言(“用例如法语说话”)或公众人物(“扮演例如拿破仑”)。为了获得兴趣爱好和公众人物的列表,作者要求LLaMA 2-Chat生成它,以避免教学和模型知识之间的不匹配(例如,要求模型扮演训练中没有遇到的人)。为了使指令更加复杂和多样化,作者通过随机组合上述约束来构建最终指令。在为训练数据构建最终系统消息时,作者也会在一半的时间内修改原始指令,使其不那么冗长,例如,“从现在起始终充当拿破仑”-> “人物:拿破仑。”这些步骤生成了一个SFT数据集,可以在该数据集上微调LLaMA 2-Chat。
为了说明GAtt如何在微调过程中帮助重塑注意力,作者在下图中显示了模型的最大注意力激活。每个图的左侧对应系统信息(“Act as Oscar Wilde,扮演奥斯卡·王尔德”)。我们可以看到,与没有GAtt的模型(左)相比,配备GAtt的型号(右)在对话的大部分时间里保持了对系统消息的大量注意力激活。(?差别很大吗)
3.4 RLHF结果
3.4.1 基于模型的评估
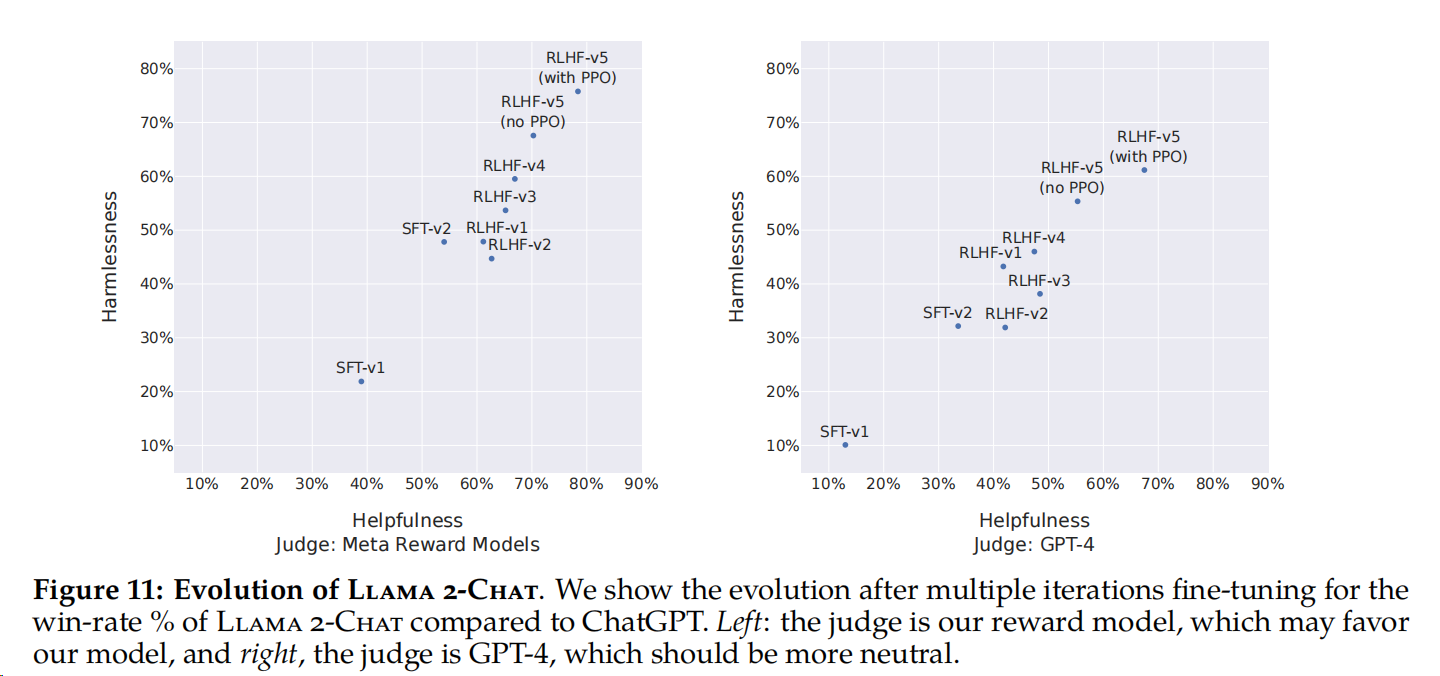
模型的进展。图11报告了作者针对安全和帮助轴的不同SFT和RLHF版本的进展,通过Meta内部的安全和帮助奖励模型进行测量。在这组评估中,RLHF-V3之后的两个轴上都优于ChatGPT(无害和有用>50%)。尽管前面提到了使用Meta的奖励作为逐点衡量标准的相关性,但可以说,它可能偏向于LLaMA 2-Chat。因此,为了进行公平的比较,作者使用GPT-4额外计算最终结果,以评估哪一代是优选的。ChatGPT和LLaMA 2-Chat输出在GPT-4提示中出现的顺序是随机交换的,以避免任何偏差。正如预期的那样,支持LLaMA 2-Chat的胜率不那么明显,尽管我们最新的LLaMA 2-Chat获得了超过60%的胜率。
3.4.2 人类评价
人类评价通常被认为是评判自然语言生成模型(包括对话模型)的黄金标准。为了评估主要模型版本的质量,作者要求人类评估人员对其有用性和安全性进行评分。作者将LLaMA 2-Chat模型与开源模型(Falcon,MPT ,Vicuna)以及4000多个单回合和多回合提示的闭源模型(ChatGPT和PaLM)进行了比较。对于ChatGPT,作者使用gpt-3.5-turbo-0301型号。对于PaLM,作者使用chat-bison-001模型。
结果如图12所示,LLaMA 2-Chat模型在单回合和多回合提示上都显著优于开源模型。特别是,LLaMA 2-Chat 7B模型在60%的提示上优于MPT-7B-Chat。LLaMA 2-Chat 34B与同等尺寸的Vicuna-33B和Falcon 40B型号相比,总体胜率超过75%。 最大的LLaMA 2-Chat模型与ChatGPT具有竞争力。LLaMA 2-Chat 70B模型相对于ChatGPT的胜率为36%,平局率为31.5%。在我们的提示集上,LLaMA 2-Chat 70B模型在很大程度上优于PaLM bison聊天模型。