从BERT到GLM,NLP经历了什么?
从BERT到GLM,NLP经历了什么?
2022年底,ChatGPT悄然进入大众的视线,受到了业内人士和广大群众的注意。ChatGPT的成功不是偶然的,是其总结前人经验、反复打磨多年才得以形成的。本篇文章将顺着现代自然语言处理方法和模型的脉络,即Transformer[1]、BERT[2]、T5[3]、GPT[4]、GLM[5]和P-Tuning v2[6]几个方面来介绍。其中Transformer是一种全新的序列转换模型,BERT、T5、GPT和GLM均为预训练语言模型,P-Tuning v2是一种对预训练语言模型进行高效微调的方法。通过以上几个部分,本篇文章对现代语言模型的学习的全过程:即结构、训练和微调均进行了介绍。其中因为内容相对重复,本篇文章对T5和GPT进行简要介绍。
一、主要研究点
在ChatGPT大火之后,各种语言模型层出不穷,比如百度的文心、讯飞的星火等。但是语言模型的研究并不是最近才兴起的。早在2017年,Google Brain就发布了一个全新的序列转换模型—Transformer,后续的语言模型,基本上都与Transformer有着千丝万缕的联系。2018年,Google公开了以Transformer作为基础的语言模型BERT,轰动一时。BERT的基础模型有110M参数,在当年属于标准大小,但是其自然语言理解能力非常强。2019年,Google公开了T5模型,该模型号称是“全能模型”,即所有的自然语言理解任务都可划分为“文本到文本”的任务,T5基础模型参数量为220M,但是最大的T5模型达到了11B,是BERT_base的100倍大小。这绝对可以称之为“大模型”了。
BERT和T5都是Google的精彩操作,而另一边的OpenAI也不甘落后,2018年, GPT-1公开,其参数量有117M;2019年,GPT-2公开,其参数量有1.5B;而2020年,GPT-3公布,其参数量已经达到了175B。
放眼国内,清华大学在语言模型上研究较早。2021年,清华大学语言模型GLM发布,意为通用语言模型(General Language Model)。目前,最大的GLM参数量已经达到了130B。
基本已经可以确定的是,小模型(低于10B参数)的能力不是很强,所以语言模型方向模型参数规模越来越大,百亿、千亿、万亿模型都不足为奇。然而,抛开预训练不谈,在如此大的规模下,大部分个人和团队都已经没有能力去做模型的全参数微调了。因此,国内外研究者先后提出了P-Tuning[7]、Prefix-Tuning[8]、P-Tuning v2[6]、Prompt Tuning[9]和LoRA[10]等部分参数微调方法。本篇文章选择了清华大学的P-Tuning v2,该方法微调效果可以与全参数微调媲美,但是微调参数量仅为全参数微调的3%左右。
本篇文章会对上述模型和技术进行简要介绍,该脉络基本涉及了现代语言模型学习的全过程。
二、Transformer
2.1 序列转换模型
一个序列转换(Sequence-to-Sequence, Seq2Seq)模型一般包括一个编码器(Encoder)和一个解码器(Decoder),如图2-1。序列转换模型并不是Transformer首次提出的。在Transformer之前,序列转换模型一般由循环神经网络(RNN)或卷积神经网络(CNN)作为编码器和解码器。然而无论是RNN也好,CNN也罢,它们都足够复杂,导致序列转换模型的效率不高。后来,有的学者尝试将注意力机制(Attention Mechanism)引入序列转换模型[11],让序列转换模型的效率得以一定的提升。不过它们仍然没有脱离RNN或者CNN。
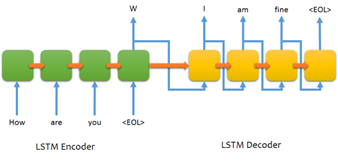
而Transformer,彻底抛弃了复杂的RNN和CNN,只依赖于注意力机制,这也是Transformer成功的关键。在介绍Transformer之前,我们首先讨论一下注意力机制。
2.2 注意力机制
注意力机制(Attention Mechanism)是人们在机器学习模型中嵌入的一种特殊结构,用来自动学习和计算输入数据对输出数据的贡献大小。在注意力机制中,我们往往会讨论Q、K、V,它们分别代表Query、Key、Value。注意力机制就是给定一个Query,经过一系列的Key来获取Value,从而得到Attention Score。如图2-2。
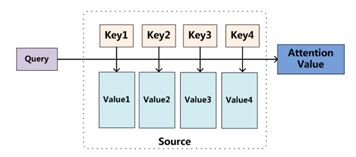
实际上,计算Attention Score的过程如下:首先,由Query和Key做向量比对,得到Query和Key的相似度,然后归一化相似度,并用相似度与Key所对应的Value做矩阵运算并求和,得到Attention Score。注意力机制公式如下:
下面我们来介绍自注意力机制。自注意力机制是注意力机制的一种。在自注意力机制中,注意力集中在上述公式中Source的内部元素,如图2-3。而在计算方式上,与传统注意力机制完全相同。在Transformer中,自注意力机制得到了应用,因为Transformer需要判断序列中词与词之间的关系强度,自注意力机制正符合这一点。

2.3 Transformer模型
Transformer是Seq2Seq的全新尝试,其抛弃了RNN和CNN作为Encoder和Decoder,采用了注意力机制,提高了Seq2Seq的效率。
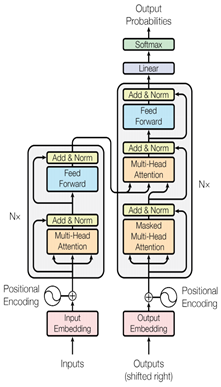
Transformer模型整体结构如图2-4。其结构可以分为输入输出嵌入向量、位置编码、Encoder模块、Decoder模块等。
对输入、输出进行向量化(Embedding)已经是广为应用的做法,其比独热编码(One-Hot)拥有更加优秀的能力,这里不再赘述。下面我们讨论位置编码。
位置编码 。因为Transformer抛弃了RNN和CNN,这样,如果不经过特殊处理,Transformer没有办法表示序列的顺序。但是,序列的顺序中往往蕴含着一些重要信息,比如:
I do not like the story of the movie, but I do like the cast.
I do like the story of the movie, but I do not like the cast.
上述两个句子序列的词完全相同,只不过是某些词的顺序不同。如果不考虑词在序列中的位置,那么Encoder会认为这两个序列完全相同。因此,选择一种合适的方式表示词在序列中的顺序非常重要。
一个好的位置编码方案需要满足以下几个条件:1.它能为每个时间步输出一个独一无二的编码;2.不同长度的句子之间,任何两个时间步之间的距离应该保持一致;3.模型应该能毫不费力地泛化更长的句子,它的值应该是有界的;4.它必须是确定性的。
位置编码可以通过训练得到,也可以通过公式计算得到。Transformer中的位置编码采用公式计算得到,公式如下:
Transformer的位置编码简单但是有创新性。该编码不是一个单一的数值,而是包含句子中特定位置信息的d维向量(d_model即隐层维数)。此外,该编码没有整合进模型,而是用这个向量让每个词具有它在句子序列中的位置信息,即通过注入词的顺序信息来增强模型的输入。最后,采用三角函数来作为位置编码公式,对于相对位置的计算更加方便,因为三角函数具有周期性。
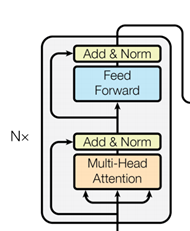
Encoder 。Transformer的编码器结构如图2-5。可以看到,Encoder部分由N个Encoder单元构成。在Transformer中,N=6。一个Encoder单元,由一个多头注意力机制(Multi-Head Attention)和一个前馈网络(Feed Forward)构成。在多头注意力机制和前馈网络完成后,会计算残差和(Add)并正规化(Norm)。首先,我们来讨论多头注意力机制。
在2.2节中,我们对注意力机制有了初步了解。在这里,我们进一步讨论Transformer中应用的注意力机制。Transformer中对注意力机制的体现在多头注意力机制。而多头注意力机制是由缩放点积注意力机制(Scaled Dot-Product Attention)构成,它是注意力机制的一种,其计算过程与注意力机制一致,其计算公式如下:
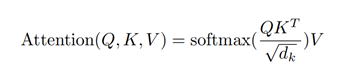
缩放点积注意力机制在做完Query和Key的点积之后,会进行一个缩放,即除以d的开方。之所以要缩放,是因为对于输入的d大值,会导致Query和Key的点积非常大,这样会导致SoftMax产生非常小的值,为了抵消这个效果,缩放点击注意力机制会进行一个缩放。
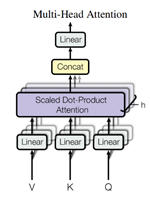
多头注意力机制如图2-6。Transformer认为,将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息。多头注意力机制就是将缩放点积注意力机制的过程做h次,再把输出合并起来。多头注意力机制的公式如下:

Encoder单元中的另一个部分是一个前馈网络。Transformer在这里设计的前馈网络比较简单,为一个两层的多层感知机,第一层有一个ReLU激活函数,第二层为一个线性变换。公式如下:
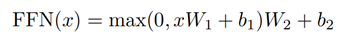
Decoder 。Transformer的Decoder和Encoder十分相似。Decoder中Decoder单元数N=6,与Encoder一致。Decoder和Encoder最大的区别,是Decoder单元中多了一层Masked Multi-Head Attention。
什么是Masked Multi-Head Attention?其实Multi-Head Attention和上述的一致。但是单纯的Multi-Head Attention是双向的,也就是某个词既可以看到它之后的词,也可以看到它之前的词。
但是在解码阶段,模型需要做的是通过已经有的信息来预测下一个位置会出现什么,如果此时模型知道了某个词之后的信息,模型就失去了“预测”,相当于看到了未来的信息。这是我们不希望发生的。所以,在解码阶段,我们希望自注意力机制是“单向”的,所以这里就用了Masked自注意力机制,组织模型看到将要预测的信息。
Decoder中的Multi-Head Attention的K V是Encoder的输出计算的。
至此,Transformer的模型结构已经介绍完成。Transformer对后来语言模型的影响十分深远,后续的语言模型,基本上都采用了Transformer或者基于Transformer修改的模型。
三、BERT
Transformer是一个Seq2Seq模型,但并不是一个实际的语言模型。而首个将Transformer应用到实际语言模型中的,正是BERT。BERT全称Bidirectional Encoder Representations from Transformers。从全称中可以看出,BERT是一个双向编码模型,并且和Transformer有关。下面我们来介绍一下BERT。
我们知道,GPT是一个自回归(Autoregression)语言模型,即,当前的Token只能看到它和它之前的Token,而不能看到它之后的Token。BERT在当时的条件下认为,这限制了预训练,特别是微调的能力。模型应该是双向的才好。因此,BERT诞生了,一个双向编码语言模型。
当然,在现在看来,我们无法评价自回归(Autoregression)模型和自编码(Autoencoder)模型,或者说单向模型和双向模型谁好谁坏,它们各有优缺点。比如,自回归语言模型更加适合自然语言生成任务,而自编码模型更加适合自然语言理解任务。
3.1 BERT与Transformer
BERT并没有把Transformer拿来直接用,而是只用到了Encoder部分。如图3-1,为BERT模型的结构图,其中蓝色阴影部分,就是Transformer的Encoder部分。可以看出,Transformer的Encoder模块,也是BERT的核心。
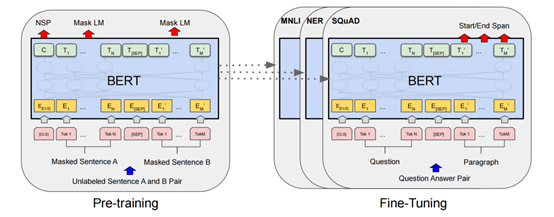
BERT只用了Transformer的Encoder部分,并且相对Transformer来说,BERT对Encoder进行了一些修改。其主要的修改如下:1.在Transformer的介绍中我们提到过,Transformer的Encoder层是由N=6的单元构成的。在BERT中,BERT_base N = 12 BERT_large N = 24。2.在Transformer中,注意力机制体现在模型中是多头注意力机制,Transformer中多头注意力机制是由h = 8,即8个缩放点积注意力叠加而成。在BERT中,BERT_base h = 12,BERT_large h = 16。3.在Transformer中,d = 512,在BERT中,BERT_base d = 768,BERT_large d = 1024。这个d其实就是模型最大能接受的Token长度。4.Embedding部分有了一些调整,多了一个Segment Embedding,Positional Embedding也有调整。我们将在下面介绍这一部分。
这样看来,BERT_base的参数规模是110M,BERT_large的参数规模是340M。虽然把这个模型放到现在看起来规模不大,但是在当时,大家的参数量还没有那么夸张。
3.2 Input Embedding
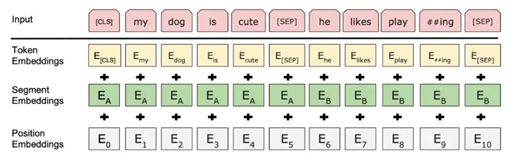
BERT相对Transformer来说,对Input Embedding部分做了一些修改,增加了一个Segment Embedding。这个是什么呢?由于BERT的主要目的是构建一个通用的预训练模型,因此难免需要兼顾到各种NLP任务场景下的输入。因此Segment Embedding的作用便是用来区分输入序列中的不同序列,其本质就是通过一个普通的词嵌入来区分每一个序列所处的位置。例如在NSP任务中,那么对于任意一个序列的每一位置都将用同一个向量来进行表示,即此时Segment词表的长度为2。
此外,BERT对Positional Embedding也有调整。Transformer中的位置编码,是由三角函数计算出来的,而BERT的位置编码,是训练出来的。
最终的Input Embedding,是这三个嵌入式张量的和:
3.3 预训练BERT
BERT的预训练没有采用传统的自左向右或者自右向左语言模型来训练BERT,而是采用的MLM,即Masked Language Model。那么具体是怎么做的呢?
MLM会随机地遮住输入的某些Token,比如:
Input: 今天天气真好呀!
MLM: 今天天气真[MASK]呀!
遮住之后,MLM的要做的事就是根据上下文来预测被遮住的Token应该是什么,是“好”,还是“坏”?这些都是根据上下文,来计算概率的。也就是在这里,可以体现出BERT是双向模型,因为这里的上下文,既包括Token左边的,也包括Token右边的。MLM根据整个句子信息来推断被遮住的Token。
根据经验,一般会MASK掉句子的15%的Token来进行训练,效果比较好(BERT的论文中没有提为什么是15%,T5论文中有对比实验,证明了15%是效果最好的)。不过,如果这15%全部把输入的Token替换成[MASK],可能会有一个问题:这会造成预训练和微调之间产生一个不匹配的情况,因为在微调的过程中,[MASK]并不会出现,这样预测的概率可能不准确。为了解决这个问题,BERT把这15%中的80%用[MASK]替换,10%不变,10%随机替换为其他Token。
接下来我们来介绍BERT中另外一个部分,Next Sentence Prediction。很多下游任务,比如问题回答、自然语言推理等,都要基于多个句子之间的关系,这个关系是没有办法被语言模型直接捕获到的。为了解决这个问题,BERT在预训练中加入了NSP。NSP是一个二分类下句预测任务。具体地,对于每个样本来说都是由A和B两句话构成,其中的情况B确实为A的下一句话(标签为IsNext),另外的的情况是B为语料中其它的随机句子(标签为NotNext),然后模型来预测B是否为A的下一句话。NSP的位置在BERT模型图中有所体现。
在实验中,BERT的效果遥遥领先于同期其他语言模型,取得了喜人的成绩。这里我们不做过多介绍。
四、T5和GPT
T5,特别是GPT,其能力大家有目共睹。本篇文章中将简单对其进行介绍。
4.1 T5模型
T5,是Transfer Text-to-Text Transformer的简写。Transfer来自Transfer Learning,预训练模型基本上属于这个范畴,Transformer即我们在第二节中提到的,那么什么是Text-to-Text?它是T5提出的一个统一框架,用于将所有的自然语言处理(NLP)任务都转化为文本到文本(Text-to-Text)任务。
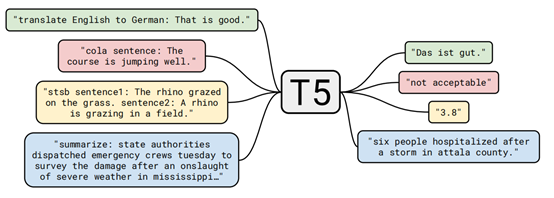
比如,自然语言处理中常见的翻译任务,在T5模型中,只需要在给模型输入的部分加上前缀:“给我从英语翻译成汉语”,然后再加上要翻译的内容即可。通过这样的方式,就可以将NLP任务都转成Text-to-Text的形式,这样,就可以用同样的模型、同样的损失函数、同样的训练过程、同样的解码过程来完成所有的NLP任务。本文对T5模型的介绍就到这里,更多内容可以阅读原论文。
4.2 GPT模型
说到GPT(Generative Pre-Training)语言模型,大家首先想起的一定是ChatGPT。ChatGPT是基于GPT-3.5的对话聊天机器人,其能力大家有目共睹。其成功的关键在于超大的参数规模(1750亿)和超多的预训练语料,这是普通公司和个人难以承受的。本篇文章将回到最初的GPT,来讨论GPT的基本结构。
GPT模型与BERT模型不同。BERT模型是自编码模型,而GPT模型是自回归模型。自回归模型对自然语言生成有着天然的优势。不过与BERT、T5模型相同,GPT同样也抛弃了传统的RNN和CNN,转而采用Transformer结构。与BERT不同的是,GPT采用的不是Transformer的Encoder部分,而是其Decoder部分。
GPT的核心部分是N=12的Transformer Decoder结构,如图4-2。
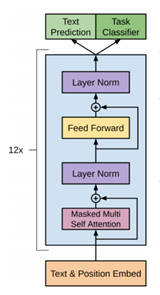
同样,GPT也并没有将Transformer的Decoder拿过来直接用,而是做了一些修改。Transformer的Decoder结构中,包含了Masked Multi Self Attention和Multi Self Attention,在GPT中,只保留了Masked Multi Self Attention。其余基本没有变化。
如今,GPT已经迎来了第四个大版本,GPT-4。其参数规模进一步增大,能力进一步增强,更是拥有了理解图像的能力。AI的能力在逐步增强。
五、GLM
在国内,清华大学发布的GLM(General Language Model)应该是效果比较不错的一个模型。当然,其优良的效果源于其创新的思想和持续的研究。
GLM意为通用语言模型,其通用性体现在哪里?我们知道,预训练语言模型可以分为三种:自回归模型(e.g. GPT[4])、自编码模型(e.g. BERT[2])、编码-解码模型(e.g. RoRERTa[12])。它们各有各的擅长之处。比如自回归模型擅长自然语言生成任务,而自编码模型擅长自然语言理解任务。在GLM之前,也有研究人员尝试将上述三种模型结合[13],以胜任多种自然语言处理任务,不过因为自回归和自编码在模型结构上相差太多,所以效果不是很好(在现在看,GPT似乎有能力处理自然语言理解和自然语言生成任务,不过在当时的条件下并没有很出色的能力)。
同样,GLM也尝试能够同时处理自然语言理解和自然语言生成等多种NLP任务。不同于之前研究的简单结合,GLM创新地应用了自回归填空思想。下面,我们来介绍GLM中的自回归填空思想。
5.1 自回归填空
GLM模型应用了名为自回归填空(Autoregressive Blank Infilling)的思想。我们给定一个文本序列[x~1~, …, x ~n~ ],在其中采用多个文本域{s ~1~ , …, s ~m~ },其中每个文本域s~i ~都对应x中的连续Token [s ~i,1~ ,…,s ~i,li~ ],而每一个文本域都会被一个单独的Token [MASK]所替代。也许通过文字描述比较难以理解。我们可以看图5-1:
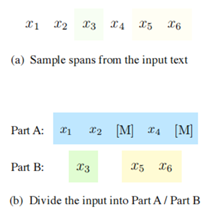
在图5-1(a)中,可以看到我们给定的文本序列为[x~1~, …, x~6~],在文本序列中采样的文本域为{s ~1~ , s ~2~ },其中s~1~对应着[x ~3~ ],s~2~对应着[x ~5~ , x ~6~ ](图中含有色块部分)。在图5-1(b)中可以看到,GLM把s~1~和s~2~对应的x部分替换为一个[MASK] Token,而与BERT等Masked不同,GLM没有选择直接丢失这些x,而是将其放到了Part B部分。
GLM随机Masked掉一些文本,其实在BERT中也是这样做的,我们称之为Masked Language Model(MLM)。只不过,在BERT中,一般Masked掉的是一个词,而GLM中可能会Masked掉连续的多个字。个人猜测,可能是因为在中文中,一个字可能意义不如多个字组成的意义大(如“玩”和“玩笑”可能差别很大),所以Masked掉多个字,可能效果会更好一些。GLM随机Masked掉的比例为15%,沿用了BERT和T5的Masked的比例,这个比例在T5模型的论文中证明,为效果最好的。
对于Masked掉的词,GLM采用自回归的方式尝试还原它们,即“自回归填空”,公式如下:
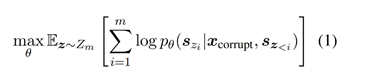
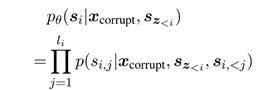
其中x~corrupt~就是partA,即带MASK部分的句子,s~z<i~指的是partB的部分,不过看到它只用了z<i的部分,也就是单向的,即自回归的。不过考虑到span之间可能也有关系,所以s~z~的顺序是随机打乱的。如图5-2。
在这里也可以看出,GLM预测的条件比BERT多了一个partB。在BERT中,MASK掉的15%的输入,其中只有80%被[MASK]替代,而另外10%不变,10%随机变为其他Token,BERT通过这种方式来保留一些被Masked的原始信息。但是GLM没有这样做,GLM把Masked掉的信息全部保留在了partB,这样可以进一步提高预测能力。不过partA是看不到partB的,partB可以自回归地看到已经走过的partB和全部的partA。
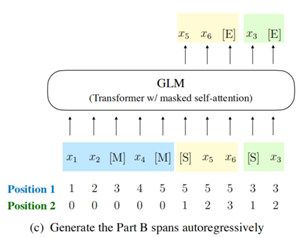
5.2 二维位置编码
在Transformer中,位置编码采用了三角函数计算的方式得到;在BERT中,位置编码采用了预训练的方式训练而得。GLM仍然是以Transformer为基础的结构,自然也没有原生的表示位置信息的能力,所以,也只能够通过位置编码的形式来获取位置信息。
与Transformer和BERT的一维位置编码不同,GLM采用了二维位置编码。
通过上一节的介绍我们知道,GLM把输入的文本分为两个部分:partA和partB。所谓二维编码,即对partA部分和partB部分都进行编码。如图5-3。
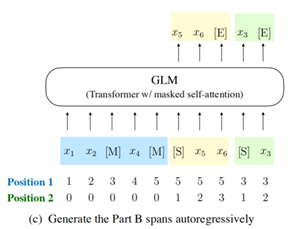
对于Position 1,表示词在partA中的位置,Position 2表示被Masked的词在partB中的位置,如果Position 2 = 0,表示非Masked的词。
5.3 GLM与Transformer
上述我们也提到,GLM同样是基于Transformer的结构,不过与BERT、T5一样,GLM同样对Transformer的结构进行了修改。GLM同样只使用了Transformer的Encoder部分,并且做了以下修改:1.重新调整了LN和残差连接的顺序。2.对于Token的预测输出用的是单个的线形层。3.将激活函数由ReLU调整为GeLUs,因为GeLUs效果更好。
至此,GLM的基本结构已经介绍完毕。四个基于Transformer的预训练语言模型也已经介绍完毕。它们整体相似,但是都有自己的创新点。相信在未来,会有更多更好的语言模型诞生。但是,为了适应下游任务,对于预训练好的语言模型,往往需要经过下游数据进行微调后才可更好的发挥它的能力。下面一节,我们介绍微调相关技术。
六、P-Tuning v2
训练语言模型的成本是巨大的,往往小的企业或者个人应用的,都是在一个良好的预训练语言模型上进行微调。从前,预训练语言模型的方式只有全参数微调(Fine-Tuning),全参数微调效果相对较好,可以让微调后的预训练模型在处理下游任务时得到良好的效果。但是全参数微调的设备需求仍然很大,比如,对于GLM-130B进行全参数微调,需要10台DGX A100服务器,设备就需要千万级别。这对很多企业和个人仍然是不能接受的。
为了减少微调的设备等资源的消耗,研究者着手设计部分参数微调的方法,包括P-Tuning[7]、Prefix-Tuning[8]、Prompt-Tuning[9]、LoRA[10]和P-Tuning v2[6]。但是,P-Tuning、Prefix-Tuning虽然实现了部分参数调优,让微调的资源消耗降下来了,但是其性能仍然不如全参数微调。LoRA同样也是一种部分参数微调的方法,其在挖掘语言模型的潜在能力上有着不错的成绩,并且其资源消耗极低,受到了大家的关注。LoRA在文生图领域应用广泛。
Prompt-Tuning和P-Tuning v2基本上是同一时期发布的,它们均基于Prefix-Tuning进行了修改和优化,结构基本一致。这里,我们选择P-Tuning v2进行介绍。
6.1 提示微调
上述我们介绍P-Tuning v2属于部分参数微调,更准确地说,P-Tuning v2应该属于提示微调(Prompt Tuning)。提示微调只用一个冻结的语言模型来微调连续的提示,大大减少了训练时的存储和内存使用。
提示微调冻结了预训练模型的所有参数,并使用自然语言提示来查询语言模型。比如,对于情感分析问题,我们可以将样本与提示“这部电影是[MASK]”串联起来,要求预训练语言模型预测被Masked的标注。然后,我们可以使用“好”与“坏”是被Masked标注的预测概率来预测样本的标签。提示微调完全不需要训练,只需要存储一份模型参数。
6.2 P-Tuning v2
P-Tuning v2并不是一个全新的方法,其事实上是将文本生成的Prefix-Tuning技术适配到自然语言理解任务中,其主要结果如下:1.仅精调0.1%参数量(固定语言模型(LM)参数),在330M到10B参数规模的语言模型上,均取得和Fine-Tuning相似的性能。2.将Prompt-Tuning技术首次拓展到序列标注等复杂自然语言理解(NLU)任务上。
P-Tuning v2的关键所在就是引入了Prefix-Tuning。Prefix-Tuning最开始应用在自然语言生成(NLG),由[Prefix, x, y]三部分构成,如图6-1。Prefix为前缀,
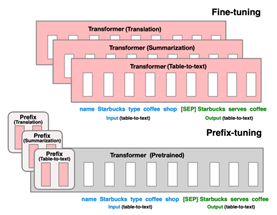
x为输入,y为输出。Prefix-Tuning将预训练LM参数固定,Prefix参数进行微调,它不仅只在Embedding层进行微调,而是在每一层都进行微调。
P-Tuning v2实际上就是Prefix-Tuning,如图6-2(b)。在Prefix部分,每一层Transformer的Embedding输入都需要被微调,这一点是不同于P-Tuning的,在P-Tuning中,只有第一层Embedding才需要被微调。这样看来,P-Tuning v2可以微调的参数变多了,假设Prefix部分由50个Token组成,那么P-Tuning v2共有50*12=600个参数需要微调。可微调的参数多了,效果自然也会好一些。
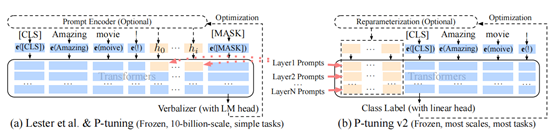
此外,P-Tuning v2还包括以下改进:1.移除了Reparamerization加速训练方式;2.采用了多任务学习优化:基于多任务数据集的Prompt进行预训练,然后再适配下游任务;3.舍弃了词汇Mapping的Verbalizer的使用,重新利用[CLS]和字符标签,跟全参数微调一样利用CLS或者Token的输出做NLU,以增强通用性,可以适配到序列标注任务。
与GLM一样,P-Tuning v2也是清华大学发布的,那么自然GLM原生地支持P-Tuning v2,并且更推荐使用P-Tuning v2对GLM进行微调。上述我们介绍,对GLM-130B进行全参数微调,需要10台DGX A100,而如果改为使用P-Tuning v2进行微调,近似性能下可以将设备减少为1台DGX A100。而对GLM进行微调同样还可以使用LoRA,虽然所需设备与P-Tuning v2几乎一致,但是其性能并没有P-Tuning v2好。
参考文献
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, pages 6000–6010.
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL 2019, pages 4171–4186.
[3] Raffel Colin, Shazeer Noam, Roberts Adam, Lee Katherine, Narang Sharan, Matena Michael, Zhou Yanqi, Li Wei, and Liu Peter J.. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 21, 140 (2020), 1–67. http://jmlr.org/papers/v21/20-074.html.
[4] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018a. Improving Language Understanding by Generative Pre-Training.
[5] Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. 2021. All nlp tasks are generation tasks: A general pretraining framework. arXiv preprint arXiv:2103.10360.
[6] Liu, X. et al. P-tuning: prompt tuning can be comparable to fine-tuning universally across scales and tasks. In Proc. the 60th Annual Meeting of the Association for Computational Linguistics. 2, 61–68 (2022).
[7] Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. 2021. Gpt understands, too. arXiv:2103.10385.
[8] Xiang Lisa Li and Percy Liang. 2021. Prefixtuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190.
[9] Lester Brian, Al-Rfou Rami, and Constant Noah. 2021. The power of scale for parameter-efficient prompt tuning. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP’21), Moens Marie-Francine, Huang Xuanjing, Specia Lucia, and Yih Scott Wen-tau (Eds.). Association for Computational Linguistics, 3045–3059
[10] Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021)
[11] Ankur Parikh, Oscar Täckström, Dipanjan Das, and Jakob Uszkoreit. A decomposable attention model. In Empirical Methods in Natural Language Processing, 2016.
[12] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv e-prints.
[13] Hangbo Bao, Li Dong, Furu Wei, Wenhui Wang, Nan Yang, Xiaodong Liu, Yu Wang, Jianfeng Gao, Songhao Piao, Ming Zhou, and Hsiao-Wuen Hon. 2020. Unilmv2: Pseudo-masked language models for unified language model pre-training. In ICML 2020,volume 119, pages 642–652.